OpenVINO实时人脸表面3D点云提取
 小o
更新于 4年前
小o
更新于 4年前
人脸3D点云提取网络介绍(facemesh)
2019年的时候有一篇在移动端实现3D点云实时提取的论文,被很多移动端AR应用作为底层算法实现人脸检测与人脸3D点云生成。该论文名称为《Real-time Facial Surface Geometry from Monocular Video on Mobile GPUs》,github有pytorch版本的实现地址如下:
https://github.com/thepowerfuldeez/facemesh.pytorch
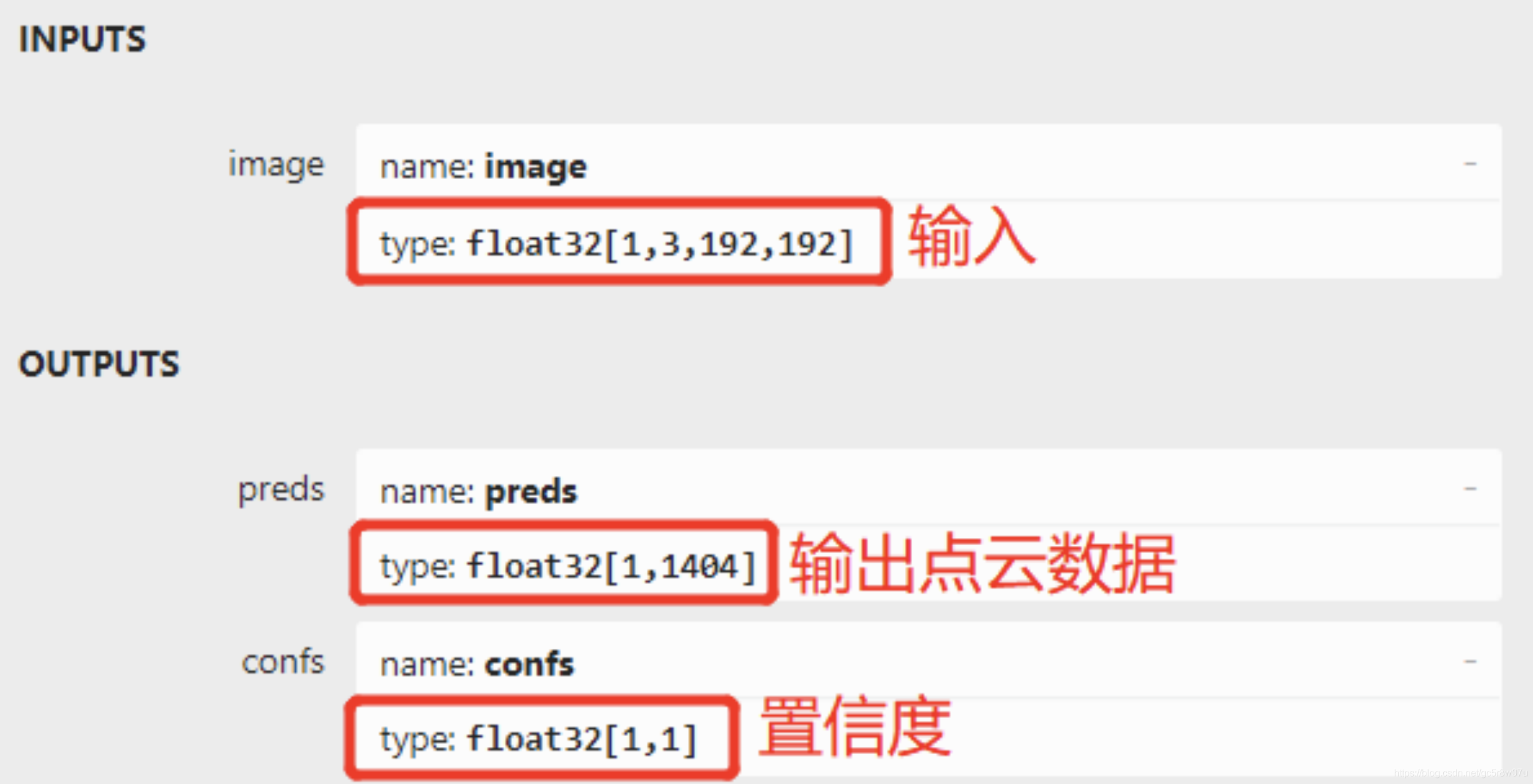
已经提供了预训练模型文件pth,可以用Netron打开查看。它的输入与输出显示截图如下:
最终输出的点云数据是468个3D坐标人脸点云坐标,输入人脸的ROI区域,大小为192x192。使用Pytorch支持的脚本可以把该模型转换为ONNX格式模型,转换的脚本与代码如下:
import torch
net = FaceMesh()
net.load_weights("facemesh.pth")
torch.onnx.export(net, torch.randn(1, 3, 192, 192, device='cpu'), "facemesh.onnx",
input_names=("image", ), output_names=("preds", "confs"), opset_version=9
这样我们就得到了ONNX版本的模型文件。
OpenVINO部署与推理facemesh
OpenVINO2020.x版本以后均支持直接读取ONNX格式模型文件,实现模型加载与推理调用。这里以OpenVINO2021.2版本为例。我们的基本思路是首先通过OpenVINO自带的人脸检测模型实现人脸检测,然后截取人脸ROI区域再送到facemesh模型中实现人脸3D表面点云468个点提取。人脸检测这里我们选择了OpenVINO自带的face-detection-0202模型文件,该模型是基于MobileNet SSDv版本,输入格式如下:NCHW = 1x3x384x384
输出格式为:
1x1xNx7
通道的顺序是BGR
从图-2得知人脸3D点云提取模型facemesh的输入格式为1x3x192x192,输出层有两个分别是preds与confs,其中preds是点云数据,confs表示置信度。Preds的1404表示的是468个点每个点的三维坐标,总计468x3=1404.代码演示部分的步骤与运行结果详解说明与步骤
加载模型与获取输入与输出信息:
# 加载人脸检测模型
net = ie.read_network(model=model_xml, weight***odel_bin)
input_blob = next(iter(net.input_info))
out_blob = next(iter(net.output*****r>
# 人脸检测的输入格式
n, c, h, w = net.input_info[input_blob].input_data.shape
print(n, c, h, w)
exec_net = ie.load_network(network=net, device_name="CPU")
# 加载人脸3D点云预测模型
face_mesh_onnx = "facemesh.onnx"
mesh_face_net = ie.read_network(model=face_mesh_onnx)
# 输入格式
em_input_blob = next(iter(mesh_face_net.input_info))
en, ec, eh, ew = mesh_face_net.input_info[em_input_blob].input_data.shape
print(en, ec, eh, ew)
em_exec_net = ie.load_network(network=mesh_face_net, device_name="CPU")
人脸检测与获取人脸ROI然后提取人脸3D点云数据
# 设置输入图像与人脸检测模型推理预测
image = cv.resize(frame, (w, h))
image = image.transpose(2, 0, 1)
inf_start = time.time()
res = exec_net.infer(inputs={input_blob: [image]})
ih, iw, ic = frame.shape
res = res[out_blob]
# 解析人脸检测,获取ROI
for obj in res[0][0]:
if obj[2] > 0.75:
xmin = int(obj[3] * iw)
ymin = int(obj[4] * ih)
xmax = int(obj[5] * iw)
ymax = int(obj[6] * ih)
if xmin < 0:
xmin = 0
if ymin < 0:
ymin = 0
if xmax >= iw:
xmax = iw - 1
if ymax >= ih:
ymax = ih - 1
# 截取人脸ROI,提取3D表面点云数据
roi = frame[ymin:ymax, xmin:xmax, :]
roi_img = cv.resize(roi, (ew, eh))
roi_img = np.float32(roi_img) / 127.5
roi_img = roi_img.transpose(2, 0, 1)
em_res = em_exec_net.infer(inputs={em_input_blob: [roi_img]})
# 转换为468个3D点云数据, 然后显示
prob_mesh = em_res["pred*****r> prob_mesh= np.reshape(prob_mesh, (-1, 3))
cv.rectangle(frame, (xmin, ymin), (xmax, ymax), (0, 255, 255), 2, 8)
sx, sy= ew / roi.shape[1], eh / roi.shape[0]
for i in range(prob_mesh.shape[0]):
x, y = int(prob_mesh[i, 0] / sx), int(prob_mesh[i, 1] / sy)
cv.circle(frame, (xmin + x, ymin + y), 1, (0, 0, 255), 1)
# 计算帧率与显示点云结果
inf_end = time.time() - inf_start
cv.putText(frame, "infer time(ms): %.3f, FPS: %.2f" % (inf_end * 1000, 1 / inf_end), (10, 50),
cv.FONT_HERSHEY_SIMPLEX, 1.0, (255, 0, 255), 2, 8)
cv.imshow("Face Detection + 3D mesh", frame)
运行显示结果如下:



https://opencv.org/how-to-speed-up-deep-learning-inference-using-openvino-toolkit-2/
Real-time Facial Surface Geometry from Monocular Video on Mobile GPU***r>https://arxiv.org/pdf/1907.06724.pdf
https://github.com/thepowerfuldeez/facemesh.pytorch